Prepare your test environment using Test Data Orchestration
When you have the recurring need to satisfy data dependencies in your test environment, use BlazeMeter's test data orchestration. The orchestration can create, read, update, and delete test data in your test environment before and after each test run. BlazeMeter can generate test data that drives the test according to your requirements; but some tests additionally depend on consistent data in the test environment.
Examples of data dependencies include:
- To test object reading, object deletion, or object updating, these objects must first be created in the test environment.
- To test unique object creation, the test environment must be a clean slate; objects from previous tests must be deleted.
- To amend your data model with unique generated IDs, you need the ability to read values from the test environment.
- The test data row used in the test must be the same as the one used in the test environment.
In these test situations, you want to prepare the environment before and after each test run. The orchestration relies on the APIs of your application under test.
This article covers the following topics:
- Introduction
- How to prepare your test environment
- Usage scenarios
- Variables and functions (prefixes) reference
Introduction
Usage example: You use orchestration before the test run to seed the test environment with users. BlazeMeter does not have access to your application's business logic and therefore cannot guess or generate your proprietary user keys synthetically. In your data model, leave the data parameter for the proprietary userKey empty and have the orchestration initialize it later, before the test run. The orchestration’s ability to read and store values (such as userKeys) from API responses ensures consistency between the seeded data and the tests.
Benefits
Using Test Data Orchestration has the following benefits.
- Orchestration is available to GUI functional tests and performance tests as part of the Test Data integration.
- Orchestration maintains data consistency by using existing data models in related tests.
- Orchestration can be automated to run together with test execution.
- Different kinds of test data can be part of the same data model.
Examples: Test data can be generated synthetically or loaded from CSV files; other values can be defined by reading existing values from your test environment.
BlazeMeter makes it easy for you to use the same data consistently and helps you manage the state of your test environments in context.
Videos
Requirements
BlazeMeter relies on the application programming interface (API) of your web application. Familiarize yourself with your application’s data model, endpoints, authentication, and usage.
If your application is only reachable within your premises, you must create a Private Location agent with Data Orchestration functionality enabled. Select this Private Location as your Publish Execution Location in the Data Target Settings.
Using Test Data Orchestration is well integrated with test data from test data entities. This article assumes that you understand test data concepts and know how to create it. To learn more, see How to Use Test Data.
Some advanced orchestration features, such as bulk publishing, require scripting knowledge. Testers without scripting experience can use the base functionality in the BlazeMeter web interface.
Concepts
- API Requests create, read, update, or delete data in a test environment before the test runs.
- Clean Up Requests create, read, update, or delete data in a test environment after the test runs.
- Data Targets are containers for API requests, Clean up requests, and their settings.
- A test can have zero, one, or more data targets associated.
- A data target can be associated with several tests.
How to prepare your test environment
This screenshot shows the Data targets tab of the Data settings window.
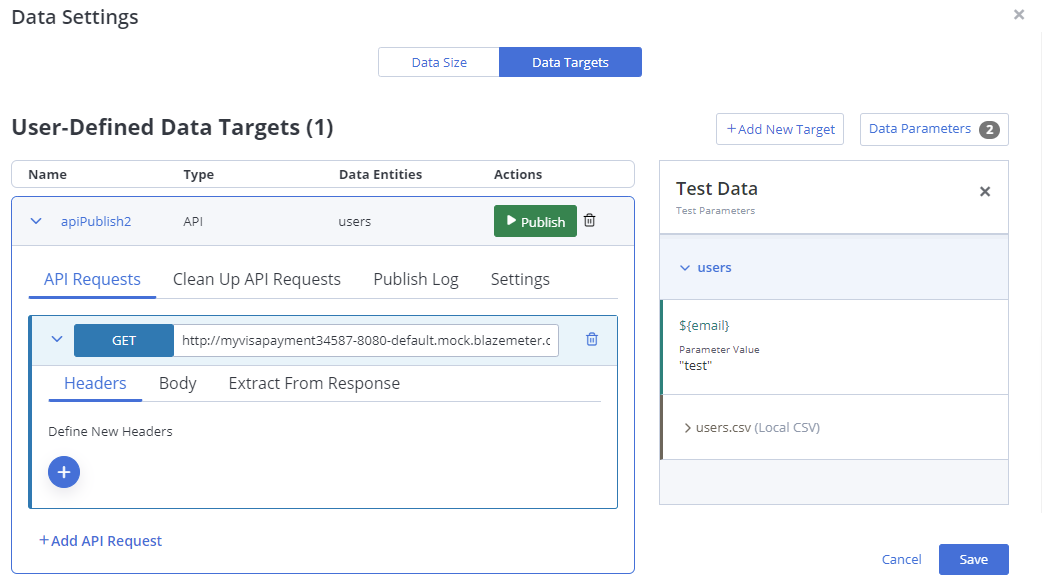
How to create a data target
This procedure assumes that you have already created test data for your test scenario.
- Open a GUI functional test or performance test.
- Open the Test configuration.
- In the Test data pane, click Data settings/Iterations.
- Go to the Data targets
- Click Add new target.
-
Choose between adding a new data target or an existing data target.
-
To create a new data target, give the data target a name that describes its purpose.
Examples: test users, daily offers, logistics Europe.
-
To clone an existing Data Target, select a data entity, and enable the checkboxes for the data targets that you want to clone. Click Add to add them to the test.
-
BlazeMeter uses these data targets to set up the environment before test execution.
For each Data Target, you first define settings, then define API Requests or Clean-Up Requests, or both. After publishing a data target, you can review log files.
Define API requests
API Requests and Clean Up Requests can create, read, update, or delete test data in your environment. You define API Requests and Clean Up Requests in Data Targets. Each test can have multiple Data Targets associated with it.
To define a Data Target:
- Open the Test Configuration.
- In the Test Data pane, click Data Settings/Iterations.
- Go to the Data Targets tab.
The tab lists the available Data Targets for this test. - Expand a Data Target to edit it.
A Data Target can contain a single or multiple requests. Multiple requests in one target are ordered and are executed in sequence.
For each API Request, follow these steps:
- Select the operation such as GET or POST.
- Define an endpoint URL.
- You can reference settings properties. For example, type
${_env.baseUrl}instead of hard-coding the hostname. - You can reference Data Parameters. Copy them from the Test Data pane and paste them into the URL field as
${_data.myvar}.
- You can reference settings properties. For example, type
- (If there are several Data Entities) Select the Data Entity in which to store this Data Target.
- Define Run Options for the request:
- Run for each Data Row — This is the default.
- Run Once — Run this request only once and not for every row. Used, for example, for one-time authentication requests.
- Go to the Headers tab
- Add Header names and values, such as
content-type. - You can copy Data Parameters from the Data Parameters pane and paste them into the Value field.
- Add Header names and values, such as
- Go to the Body tab:
- Define attributes and values in the request body.
- Parameterize the body by mapping Data Parameters to API call parameters. Copy Data Parameters from the Data Parameters pane and paste them into Body values.
- (Optional) Go to the Extract from Response tab to extract response values.
- (Optional) Go to the Response Actions to handle exceptions.
Define clean up API requests
Use this tab to set up requests that clean up the environment and reset it for the next test run.
Clean Up API Requests are defined in the same way as API Requests. The only difference is that API Requests run before test execution, and Clean Up API Requests run after test execution.
Define settings
First define important settings for the Data Target (such as your baseUrl) and Run Options.
- Open a GUI Functional test or Performance test and go to the Test Data pane.
- Click Data Settings and then go to the Data Targets tab.
You see the list of data targets. If the list is empty, create a data target first. - Open a Data Target and go to the Settings tab.
- Define Run Options.
- Define Publish Execution Location.
- Define Configuration Properties.
- Define Private Properties.
Settings: Define run options
- Run for each Data Row
Enable this option if you are using multiple rows of test data. BlazeMeter posts the sequence of API Requests once for each row, each time with different test data values. This is the default. - Run Once
Enable this option to shorten the whole publish cycle down to one execution, no matter how many iterations are defined. Running only once saves time, for example, while debugging.
Settings: Define the publish execution location – cloud or on premise
The default location is the BlazeMeter cloud. You select a different Publish Execution Location in the Data Target Settings. If your application under test can be reached through the internet by BlazeMeter, keep the default location. In this case, you do not need to create a Private Location.
If your application is only reachable on-premises within your internal network, you must create a Private Location with Data Orchestration to use this feature.
To create a Private Location:
- Click the Cog icon
 at the top right of the BlazeMeter UI to open the Settings.
at the top right of the BlazeMeter UI to open the Settings. - Go to Settings > Workspace > Private Locations.
- Click the Plus to add a new Private Location and configure it as needed.
- Under Functionalities, enable the Data Orchestration toggle.
- Click Apply.
Now you can select the Private Location as the Publish Execution Location in the Data Target Settings and use orchestration on your premises.
Settings: Define configuration properties
Define variables, such as your API's base URL, your proxy settings, and required credentials. You can reference these properties in your Data Targets later. Storing environment values, such as your hostname, in variables makes maintenance easier because if for example your baseUrl ever changes, you have to update it only once, here.
baseUrl-- Enter your hostname here.withCredentials-- Enter a boolean value whether cross-site Access-Control requests should be made using credentials such as cookies or authorization headers.auth.usernameauth.passwordxsrfCookieNamexsrfHeaderNameproxy.protocolproxy.hostproxy.port
For example, for a search request, you reference the baseURL variable in the Endpoint URL field of the API Request as follows:
${_env.baseUrl}/search
Settings: Define private properties
Define variables for your authentication tokens or required credentials. These values are never shown in users' UI screens nor log files, instead, they appear only obfuscated as ##PRIVATE_VARIABLEname##.
-
proxy.auth.username -
proxy.auth.password
For example, for an auth request, you reference the password as follows:
${_env.proxy.auth.password}
Run orchestration adhoc (debugging)
After defining the API Requests and Cleanup Requests, run an adhoc publish to verify the environment is prepared as expected. Review the Publish Log inside the Data Targets tab when debugging adhoc runs.
- Open the test and go to the Test Data pane.
- Click Data Settings and then go to the Data Targets tab.
- Identify the Data Target that you want to verify and click Publish.
- Expand the Data Target entry.
- Go to the Publish Log tab and review the outcome.
For each API Request step, the log contains a numbered step section. Steps are executed one after the other. By default, each step is executed multiple times, once for each row of test data. For example, if you have three API Requests (three steps) and ten rows of test data, the log contains 30 published entries in total. Review the body that you sent, the responses that were received, the values that were extracted, and response error codes if any.
Run orchestration automatically
For everyday use, set up automatic Test Data Orchestration as part of a Test Definition. This way, the test environment is prepared automatically every time the associated test runs.
After the test run, you’ll find the Orchestration logs as part of the test execution log.
How to edit data targets
- Open the GUI Functional test or Performance test and go to the Test Data pane.
- Click Data Settings and then go to the Data Targets tab.
- In this window, you can perform the following actions:
- Expand a Data Target to edit it inline.
- Click the Delete icon to remove a Data Target.
- Click Add New Data Target to create a new one.
- Click Save.
Review the log files
When the data target is associated with a test, you find the logs as part of the test execution log. The files are called blazedata-api-publish.log and blazedata-api-unpublish.log.
After running the orchestration adhoc, you find a Publish Log in the Data Target definition window. In the Test Data pane, click Data Settings, go to the Data Target tab, expand the data target, and go to the Publish Log tab.
Usage scenarios
Reference test data in Orchestration
One of the main features of the orchestration is ensuring consistency with your existing test data. To achieve that you replace hard-coded values in your orchestration with Data Parameters. This procedure assumes that you have already created test data for your test scenario and that you have loaded these data entities in the Test Data pane of your test configuration. You can always add more Data Parameters and Data Entities as needed.
To use test data in the orchestration, follow these steps:
- Go to the Data Targets tab and expand a Data Target to edit it.
- Click Test Data to open a read-only Test Data pane.
The pane lists Data Parameters that are available to the test. - Click the button next to a Data Parameter to Copy the parameter name to the clipboard.
- Return to the Data target and paste the Data Parameter to replace a hard-coded value.
Example: Replace the call
PUT https://my.org/api/v1/users/123?membership=true
with the following request that uses the Data Parameter id instead:
PUT https://my.org/api/v1/users/${_data.id}?membership=true
Extract response values
An API Request in a Data Target can optionally read a value from the response and assign it to a local variable or Data Parameter. Reference the variable after this Data Target step was executed.
- Go to the Data Targets tab and expand a Data Target to edit it.
- Select a Request that returns a value, for example:
POST https://my.org/api/v1/users - Go to the Extract from Response
- Click the blue Plus button and select an existing Data Parameter from the list or create a local variable.
- Select the Source of the value, either the response body or header.
- Under Content Selection, choose one of the following selection methods:
- (for Headers and Body) Regular Expression
- (for Body) JSON Pointer (JSONPointer syntax)
- (for Body) XPath
- Enter the response attribute that you want to assign to the variable.
For example, to extract the first element of the JSON array named "result", use /result/0. To extract an identifier named id, use /id, and so on.
Best Practices:
- If the extracted value is temporary and used only inside the orchestration (such as an authentication token, cookie, or session ID), click into the Variable Name field and Add a Local Variable for it.
Example: In the orchestration, you reference a local variable named token as ${_var.token}. - If you want to reuse the extracted value in the test later, click into the Variable Name field and select an existing Data Parameter to store it.
Example: You have left the userKey parameter empty in the Data Entity. As part of the orchestration, you publish data and extract a valid key value from the response. In the orchestration, you reference the data parameter named userKey as ${_data.userKey}. In a BlazeMeter test, you reference it as ${userKey}.
Handle exceptions using response actions
The API requests sent by the Orchestration return server response codes, such as 200 OK, 201 Created, network errors, permissions errors, client errors, or server errors. Certain responses are expected or can be ignored, while others might render your test results invalid. Therefore, you can optionally react to server responses and choose whether you want to fail the whole test or just skip one row of publishing.
All Response Actions skip the current iteration that triggered .
The following Response Actions are available:
|
Stop Iteration: |
Continue with orchestration |
Continue with test, including incomplete rows |
|---|---|---|
|
Stop Publishing: |
Stop the orchestration |
Continue with test, including incomplete rows |
|
Stop Publishing & Test: |
Stop the orchestration |
Fail the test |
|
Exclude Data Row for Test: |
Continue with orchestration |
Continue with test, excluding incomplete rows |
| Wait and Repeat Until | Repeats the orchestration request and waits a configurable amount of time until the condition is met, then runs the next orchestration request. If condition is not met, it stops after 5 minutes. | Continue with test |
To define your response handling for each Data Target, use the Response Actions tab.
- Go to the Data Targets tab and expand a Data Target to edit it.
- Go to the Response Actions
- Under Fallback Assertion, select the Action to trigger if publishing does not return a response. The default Action is Stop Iteration. "Network Error" is the only Fallback Assertion.
- Click the Plus button to add as many Response Actions as needed.
- Select whether you want to react to either the server response code or body:
- HTTP Response Code
- Select a response code or a response category.
- Select an Action to trigger.
- Response Body
- Select a comparison: Equals, Contains, XPath Field match, JSON Pointer match, Regular Expression match.
- Enter a value to match.
Example: You match a field named category as /category, using JSON Pointer syntax. - Select an Action to trigger.
- HTTP Response Code
- Click Save.
Publish data in bulk (advanced request body handling)
The approach shown above assumes that you want to publish or delete only a small number of objects. You manually create a handful of data targets, you use Data Parameters to handle test data, and publish the orchestration with the test.
However, to initialize multiple objects in the environment, it would be too tedious to manually create POST API Requests for, say, hundreds of test users. How can BlazeMeter make this effort easier for you?
- Some APIs accept an array of values in a single request. If your API supports such bulk operations, you can use templating. Templating lets you provide an array of data in a single request body.
- Do some initial values have dependencies on other values? To automate the orchestration even further, BlazeMeter even supports conditional logic and filters to impose constraints on the array.
- For example, the following template initializes the value of balanceType with either the string “HI” or “LO”, depending on the accountBalance value being greater or less than the given threshold:
"balanceType" : "${_fn.condition(_data.accountBalance < 200, "LO", "HI")}'
Template Syntax: Wrap templates in single quotes and format them as one line; alternatively, escape newline characters with backslashes. Reference variables with the appropriate namespace prefix.
You can use these templates in the API Request URL, Headers, and Body.
Basic template variables
You can reference any custom or default property in the body or URL of a Request:
- ${_data.parameterName}
References the value of a data parameter named “parameterName”. - ${_data.entityName.parameterName}
References a unique data parameter in a Data Entity. If two Data Entities contain a Data Parameter of the same name, use this dotted notation to specify which one you mean.
Usage Example: If the "Users" and the "Accounts" Data Entities both contain anidData Parameter, resolve the conflict by referencing one as${_data.Users.id}and the other as${_data.Accounts.id}. - ${_data.entityName.ALL}
Returns an array of all generated test data for the Data Entity entityName. From here you can use an array index to access the rows of data, and then the parameter name to access the data.- Usage example 1: To convert the "Accounts" Data Entity to JSON, use
.ALLtogether with_fn.json():
${_fn.json(_data.Accounts.ALL)} - Usage example 2: To return a comma-separated list of all data parameter names inside the "Accounts" data entity, use:
${Object.keys(_data.Accounts.ALL[0]).join(", ")} - Usage example 3: To get the value of the parameter named
accountNofrom the first row of the "Accounts" data entity, use:${_data.Accounts.ALL[0].accountNo}
- Usage example 1: To convert the "Accounts" Data Entity to JSON, use
- ${_env}
Returns environment variables defined on the Settings tab under Configuration Properties. You can identify environment variables by the _env. prefix.
The following variables are available:- ${_env.baseUrl}
- ${_env.withCredentials}
- ${_env.auth.username}
- ${_env.auth.password}
- ${_env.xsrfCookieName}
- ${_env.xsrfHeaderName}
- ${_env.proxy.protocol}
- ${_env.proxy.host}
- ${_env.proxy.port}
- ${_env.proxy.auth.username}
- ${_env.proxy.auth.password}
Basic functions in templates
Templates support the following functions in ${_fn.functionname} format. All arguments are mandatory, optional arguments are marked with a question mark. Mutually exclusive alternatives are separated by a pipe symbol “|”.
- ${_fn.condition(condition: boolean, trueValue: any, falseValue?: any)}
If the condition evaluates to true, this function returns trueValue, otherwise it returns falseValue, if defined. Providing the falseValue is optional. - ${_fn.json(obj: any)}
This function converts any object to JSON format. - ${_fn.sizeOf(data: entityName | array)}
This function returns either the number of rows of a Data Entity, or the length of an array. - ${_fn.each: (data: entityName | array, callbackFunction, template: string, separator: string = "")}
Use this function to filter data, sort it, or return a subset.- The
${_fn.each()}functions loops over all rows of generated data of entity entityName, or over all items in the given array, respectively. - Write a template that contains the property name that you want to return as an array.
- The
For each item, each() optionally calls a callback function. You can optionally filter, sort, or modify the rows by using supported functions. You do not need the _data. prefix when referencing Data Parameters inside callback functions.
The following callback functions are supported inside each():
-
${_fn.filter(propertyName: string, operator: string, value: string)}
Returns only items where a property has a certain value. Operator can be “>” or “<” or “=”.${_fn.sort(propertyName: string)}Returns the items sorted alphabetically by the value of the given property.${_fn.left(n: number)}Return the first n items.${_fn.right(n: number)}Returns the last n items.${_fn.slice(start: number, end: number)}Return the subset of items from start to end index.
Lodash functions in templates
Templates support scripting functions from the Lodash library in ${_fn._} format. Examples include ${_fn._.reverse()}, ${_fn._.fill()}, ${_fn._.findIndex()}, ${_fn._.join()}, ${_fn._.uniq()}, and many more.
For a full list, see the function list and argument syntax here: https://lodash.com/docs/4.17.15
Template examples
The below examples assume the following test data has been generated for the Data Entity Accounts:
|
id |
accountNo |
accountName |
accountBalance |
|
1 |
0752284437/9449 |
OGrpaqvvKZ |
100 |
|
2 |
2227473859/9389 |
OGrpaqvvKZ |
100 |
|
3 |
7623787625/7673 |
fGnAe5oqj7 |
1000 |
|
4 |
8405199392/0901 |
yhjdZs0LLw |
1000 |
|
5 |
2394682082/4402 |
KIK5n805eM |
1000 |
Basic template - Input (Run for Each Data Row):
The following is an example of a request body definition that assigns four values:
- It uses a function to count how many rows are in the data set, and assigns that number to the variable
accountsCount. - It maps the
accountNoandaccountBalancevalues to the respective Data Parameters. - It uses a conditional function that assigns either the string "HI" or "LO" to the
balanceTypeparameter, depending on whetheraccountBalanceis higher or lower than the threshold value 200.
{
"accountsCount": ${_fn.sizeOf(_data.Accounts)},
"accountNo": "${_data.accountNo}",
"accountBalance": "${_data.accountBalance}",
"balanceType": "${_fn.condition(_data.accountBalance < 200, "LO", "HI")}"
}
Basic template – iteration results:
In five iterations you send five distinct request bodies, one by one, with the following sample contents:
{
|
{
|
{
|
{
|
{
|
Lodash library template 1 - Input (Run for Each Data Row):
The following is an example of a request body definition that assigns the account name data parameter to the account name. It also uses an upper-case function to assign the account name in all upper case to accNameUpper.
{
"accName": "${_data.accountName}",
"accNameUpper": "${_fn._.toUpper(_data.accountName)}"
}
Lodash library template 1 – iteration results:
In five iterations you receive five distinct request bodies with the following sample contents:
{
|
{
|
{
|
{
|
{
|
Advanced template 1 – Input (Run Once):
This example sends a single request body with an array of values taken from all rows in the test data, separated by comma. The accountNo reference within the each() loop is inside the _data.Accounts entity and does not need the _data. prefix.
{ "allAccountsNo": [ ${_fn.each( _data.Accounts, '"${accountNo}"', "," )} ] }
Advanced template 1 – result:
In a single iteration, you receive one request body with the following sample content:
{
"allAccountsNo": [
"0752284437/9449",
"2227473859/9389",
"7623787625/7673",
"8405199392/0901",
"2394682082/4402"
]
}
Advanced template 2 – Input (Run Once):
This request sends a single request body with an array of values taken from all rows in test data, sorted according to the values of the property accountNo. The accountNo reference within the each() loop is inside the _data.Accounts entity and does not need the _data. prefix.
{ "allAccountsNo":
[ ${_fn.each(
_data.Accounts, _fn.sort("accountNo"), '"${accountNo}"', ","
) } ]
}
Advanced template 2 – result:
In a single iteration, you receive one request body with the following sorted content:
{
"allAccountsNo": [
"0752284437/9449",
"2227473859/9389",
"2394682082/4402",
"7623787625/7673",
"8405199392/0901"
]
}
Advanced template 3 – Input (Run Once):
This request returns certain rows using a filter. It loops over the five rows in Accounts and checks whether a value, here the id, is larger than three. If the id is larger than three, it adds the accountNo value to the array, separated by comma. The id and accountNo references within the each() loop are inside the _data.Accounts entity and do not need the _data. prefix.
{ "allAccountsNo":
[ ${_fn.each(
_data.Accounts, _fn.filter("id", ">", 3), _fn.sort("accountNo"), '"${accountNo}"', ", "
) } ]
}
Advanced template 3 – result:
In a single iteration, you receive one request body with the following sorted and filtered content:
{
"allAccountsNo": [
"2394682082/4402",
"8405199392/0901"
]
}
Advanced template 4 - Input:
This example shows a longer template inside the each() loop that returns an array with multiple elements. The template has to be wrapped in single quotes and must be on a single line. If you want to format the template with line breaks, escape the new lines with backslashes inside the template. The following two variants are valid and equivalent:
The template on one line (in bold):
{
"number_of_users": ${_fn.sizeOf(_data.users)},
"users": [
${_fn.each(
_data.users,
'{"first_name": "${firstName}", "last_name": "${lastName}"}',
","
)}
]
}
The same template reformatted with backslashes before newlines:
{
"number_of_users": ${_fn.sizeOf(users)},
"users": [
${_fn.each(
_data.users,
'{\
"first_name": "${firstName}",\
"last_name": "${lastName}"\
}',
","
)}
]
}
Advanced Template 4 - Result:
{
"number_of_users": 3,
"users": [
{
"first_name": "Nicolette",
"last_name": "Pandey"
},
{
"first_name": "Angie",
"last_name": "Morgan"
},
{
"first_name": "Katherine",
"last_name": "Yoshioka"
}
]
}
Variables and functions (prefixes) reference
Remember the following prefixes to distinguish namespaces used in Orchestration:
- _data. prefix
References test data parameters used in orchestration.
Example:${_data.streetaddress} - _env. prefix
References orchestration configuration properties.
Example:${_env.baseUrl} - _var. prefix
References local variables extracted from the response of the previous API request.
Example:${_var.cookies} - _fn. prefix
Identifies built-in basic template functions.
Example:${_fn.sizeOf()},${_fn.each()}, and more - _fn._. prefix
Identifies functions from the Lodash library.
Example:${_fn._.findIndex()}
For prefix usage examples, see Template Examples and Extract From Response.